CVPR正在进行中,中国科研力量再次成为场内外焦点之一。 日前,AI顶会常客选手商汤科技,已经披露了今年成绩单:50篇论文入选,其中还有9篇被录用为Oral、Highlight。 这些成果,既是商汤科研和技术实力的最新证明,也透露着这家知名AI公司对于产业趋势和技术趋势的预判—— 论文涉及自动驾驶、机器人等前沿方向。 大规模视觉语言基础模型:InternVL 商汤科技、上海AI实验室等联合设计了一个大规模的视觉语言基础模型——InternVL。 首次将大规模视觉编码器扩展到60亿个参数,与LL...
CVPR正在进行中,中国科研力量再次成为场内外焦点之一。
日前,AI顶会常客选手商汤科技,已经披露了今年成绩单:50篇论文入选,其中还有9篇被录用为Oral、Highlight。
这些成果,既是商汤科研和技术实力的最新证明,也透露着这家知名AI公司对于产业趋势和技术趋势的预判——
论文涉及自动驾驶、机器人等前沿方向。
大规模视觉语言基础模型:InternVL
商汤科技、上海AI实验室等联合设计了一个大规模的视觉语言基础模型——InternVL。
首次将大规模视觉编码器扩展到60亿个参数,与LLM进行对齐,在准确性、速度和稳定性之间取得了良好平衡。

论文:https://arxiv.org/abs/2312.14238
为了有效训练大规模视觉语言基础模型,InternVL还引入了一种渐进式图像-文本对齐策略。
该策略最大限度地利用网络规模的噪声图像-文本数据进行对比学习,并将细粒度、高质量的数据用于生成学习。

通过验证,相较于当前最先进的视觉基础模型和多模态大语言模型,InternVL在广泛的通用视觉语言任务上能够取得更领先的结果。

另外,InternVL工作的最新版本InternVL 1.5具备强大的视觉编码器和更深层次的场景理解能力。
InternVL 1.5支持动态高分辨率,能够准确识别和理解图像中的各种细节以及文字信息。
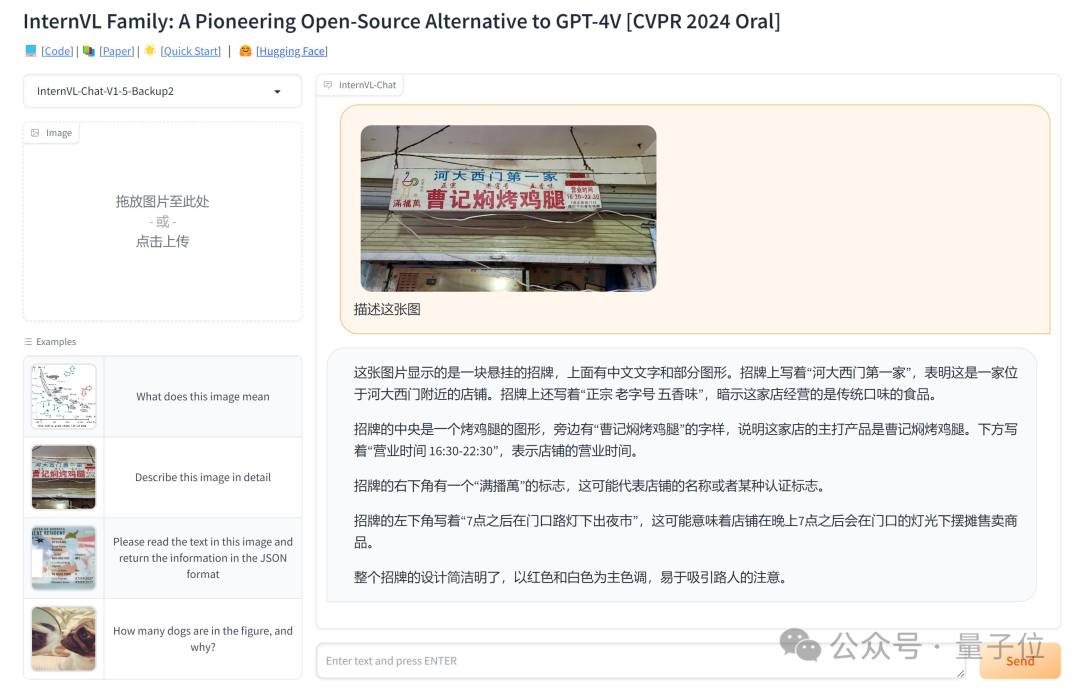
Demo:https://internvl.opengvlab.com/
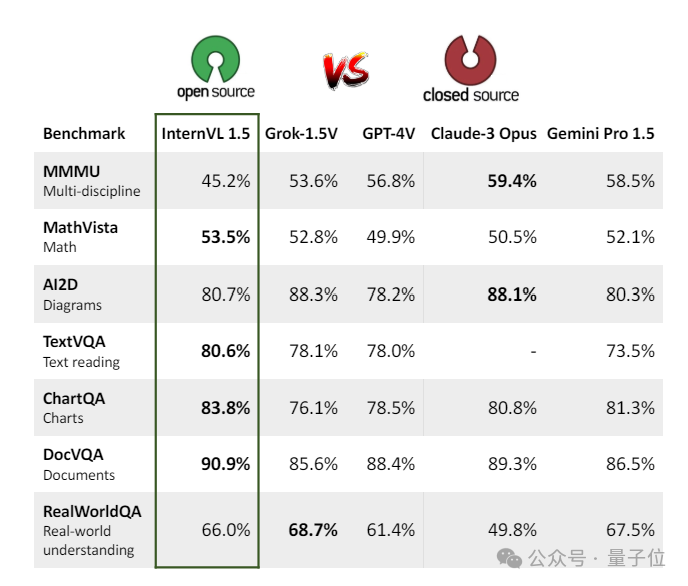
第三方评测结果显示,InternVL 1.5在多模态感知、通用问答、文档理解、信息图表理解以及数理理解等方面综合能力领先开源模型,比肩GPT-4V、Gemini Pro等闭源模型。
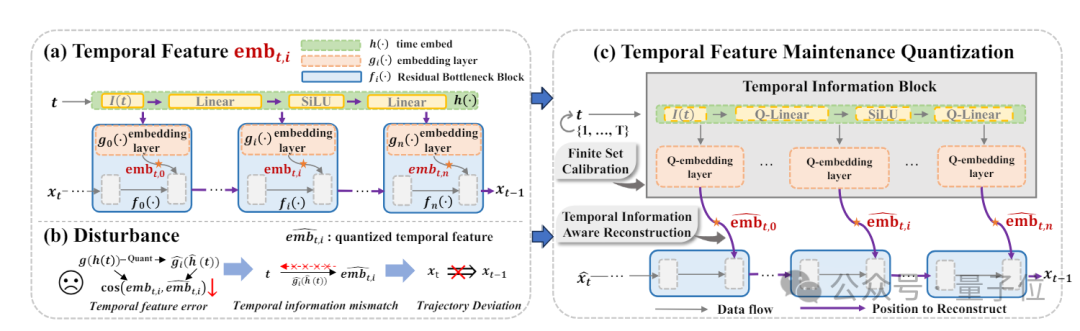
不仅如此,为了补充多模态系统在高质量图像生成中的优质表现,对传统模型进行优化,商汤还提出了一个“基于时间信息块的时间特征维护量化(TFMQ)”扩散模型框架。
论文:https://arxiv.org/abs/2311.16503
该框架时间信息块仅与时间步骤相关,与采样数据无关,创新地设计并引入了时间信息感知重建(TIAR)和有限集校准(FSC)方法,从而可以在有限的时间内对齐全精度时间特征,最小化精度损失的同时提高图像生成效率。
配备此框架,可以保持最多的时间信息并确保端到端的图像生成质量。在各种数据集和扩散模型上的广泛实验证明了该技术已经达到SOTA水平。
场景级3D开放世界感知算法:RegionPLC
场景级别的3D开放世界感知是机器人领域非常重要的能力之一。
它能够使机器人在复杂、多变的环境中自主导航、理解和交互,从而提升执行复杂任务的效率、准确性和安全性。
商汤科技和联合实验室的研究团队提出了一种直接结合点云和自然语言的新开放世界理解算法——RegionPLC,无需额外训练就可以和大语言模型结合进行一些场景级别的开放问答。

论文:https://arxiv.org/abs/2311.16503
该算法扩展到了更细粒度的区域级别点云和语言的结合,能够生成更密集和细粒度的描述。
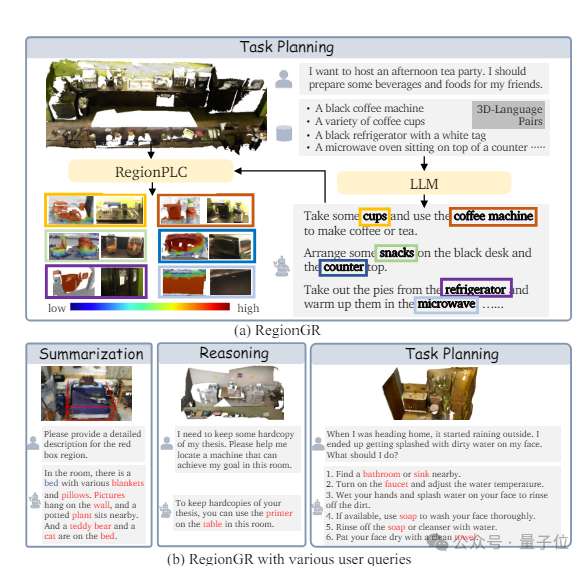
在该研究中,研究人员设计了一种基于互补的数据混合策略SFusion,只会混合在3D空间中互补的3D-text pairs,减少在优化时产生冲突的概率。这样的设计使得RegionPLC可以结合不同2D大模型的优势,达到更好性能。
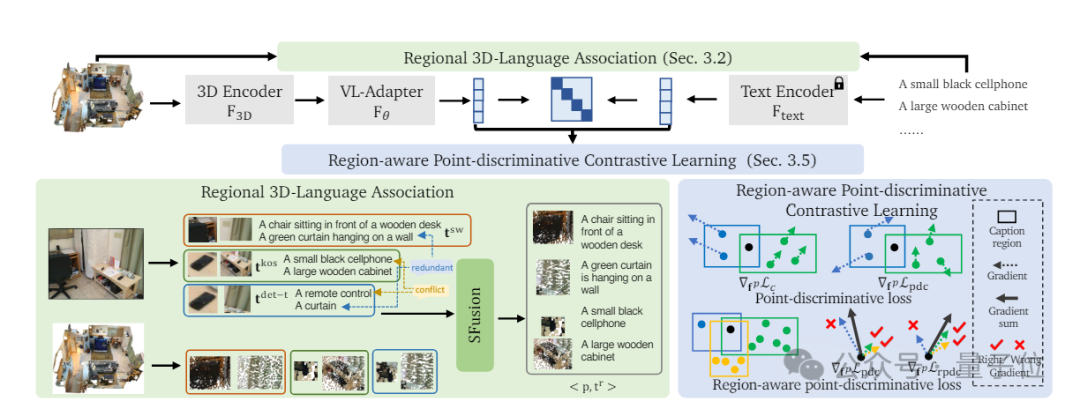
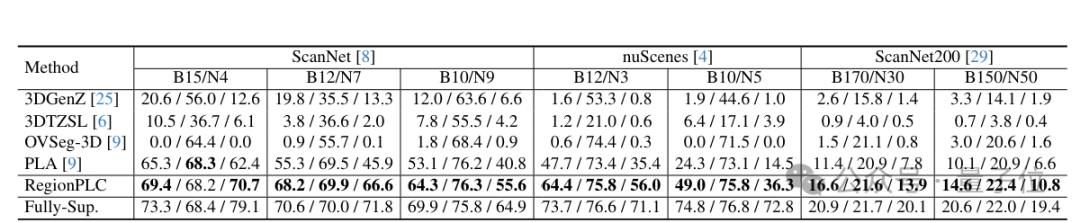
通过大量实验证明,RegionPLC在ScanNet、ScanNet200和nuScenes数据集上的性能优于现有的3D开放世界场景理解方法,并在具有挑战性的长尾或无注释场景中表现非常出色。
除了对场景的识别和理解,智能体的社会化交互能力也是人工智能迈向更高阶的关键所在。
为此,商汤及联合实验室提出了“数字生命计划(Digital Life Project)”,即通过AI技术和动作合成技术创造出能够在数字环境中模拟交互的自主3D虚拟角色。

论文:https://arxiv.org/abs/2311.16503
这些角色不仅可以进行对话,还将拥有自己的人格,并感知所处的不同社交环境,做出相对应的身体动作来表达情感和反应。

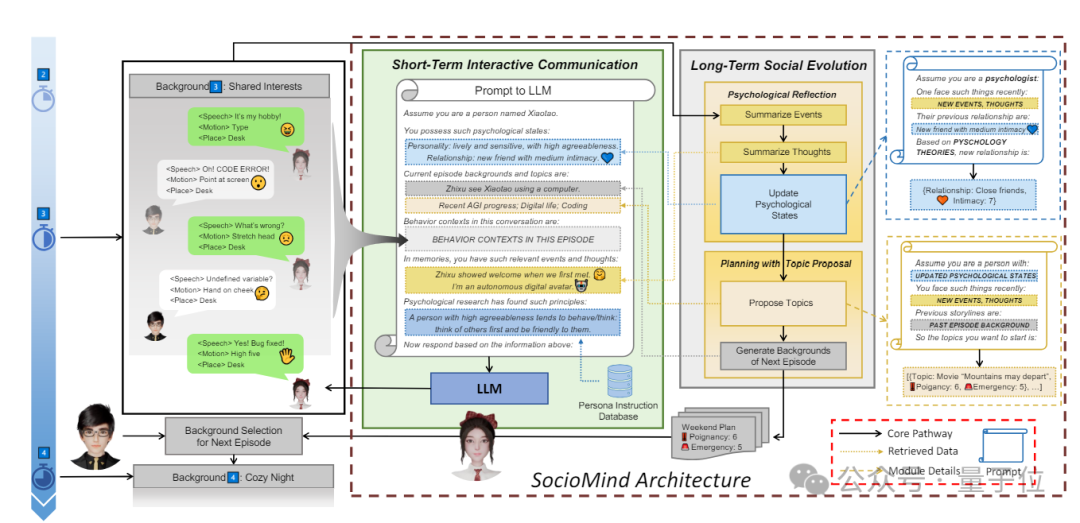
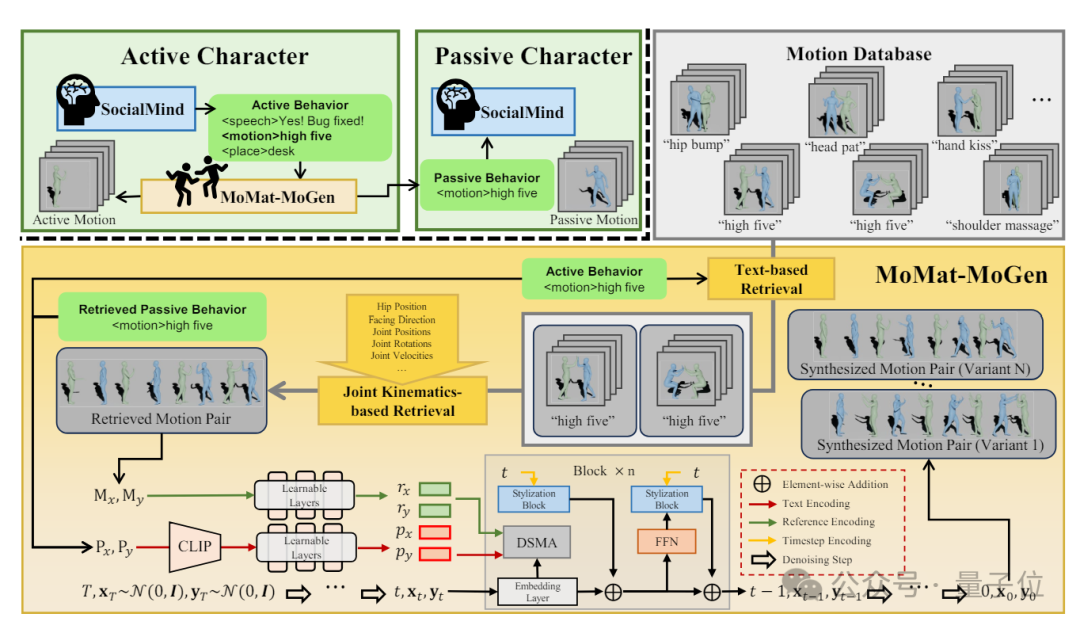
数字生命计划包括“SocioMind”和“MoMat-MoGen”两个核心部分。
其中,SocioMind是一个模拟人类思想和判断的数字大脑。它能够结合大语言模型和基于心理学原理的反思过程,使角色自主地发起和参与对话,规划接下来的故事发展。
而MoMat-MoGen是一套用于控制角色身体动作的3D系统。它结合了动作匹配(Motion Matching)和动作生成(Motion Generation)技术,在数字大脑的驱动下,让角色能根据场景做出合理的反应。
CVPR最佳论文发布在即
本次CVPR共有来自全球的2719篇论文被接收,录用率为23.6%,相较去年下降2.2%。可以看到,其他国内玩家也表现不俗,都有不少论文入选。
比如像腾讯优图实验室,此前曝光称有20篇入选,覆盖多模态、人脸识别、视觉分割等多个方向。
这周,CVPR2024在美国西雅图正在进行中。
也就在这两天,CVPR最佳论文奖即将出炉,可以期待一下。
